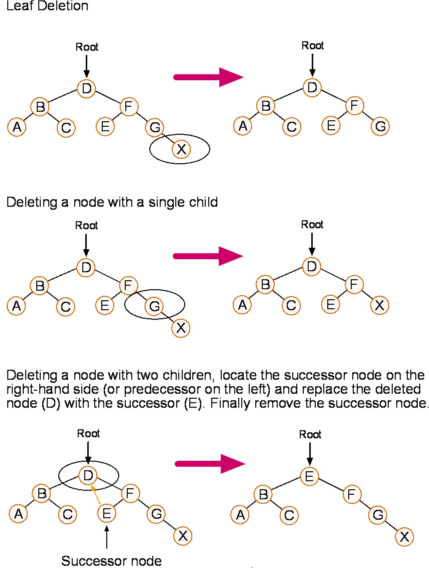
Last week, we have already learnt the structure of Binary Tree. A binary tree consists of a finite set of nodes that is either empty, or consists of one specially designated node called the root of the binary tree, and the elements of two disjoint binary trees called the left subtree and right subtree of the root. We know that when inserting a new node to a tree, we first need to make comparison with the root of each node. If the new node is smaller than the root, it will be placed to its left subtree. Otherwise, it will be placed to its right subtree. It will continue this comparison until the new node find an empty place to be placed. This kind of structure is easy to trace in an "Insert" algorithm. However, from my perspective, it is hard to think about how deletion work in Binary Search Tree. After the class, I find out that there are three possible cases to consider and according to the Professor, there are three ways to solve deletion problems.
- Deleting a node with no children: simply remove the node from the tree.
- Deleting a node with one child: remove the node and replace it with its child.
- Deleting a node with two children: call the node to be deleted N. Do not delete N. Instead, choose either its in-order successor node or its in-order predecessor node, R. Copy the value of R to N, then recursively call delete on R until reaching one of the first two cases. If you choose in-order successor of a node, as right sub tree is not NIL (Our present case is node has 2 children), then its in-order successor is node with least value in its right sub tree, which will have at a maximum of 1 sub tree, so deleting it would fall in one of first 2 cases.
Here, we can see that using this picture, we can understand this algorithm better.
From this example, we can see that when we are dealing with more complicated binary tree deletion like deleting node with two subtrees, we can either use the largest node in left subtree or use the smallest node in right subtree. From this lesson, I find out that using tree diagram and tracing will help us better learn this subject. Because binary tree is an ordered tree, we can use this to apply to other data set so that it will save us a lot of time to search for a certain number. Also, in class, we also learnt about the importance of a balanced tree. A balanced tree, which have similar number of right and left trees will be the best and most efficient in doing searching.